Apollo GC调优
Apollo携程现状
Apollo(点击跳转到Github)作为携程新一代的配置中心,目前线上部署10台Config Server,服务于3.5w+客户端。
今天要讨论的是一次Apollo的JVM调优。
调优前
调优前Cat记录GC信息如下图所示:
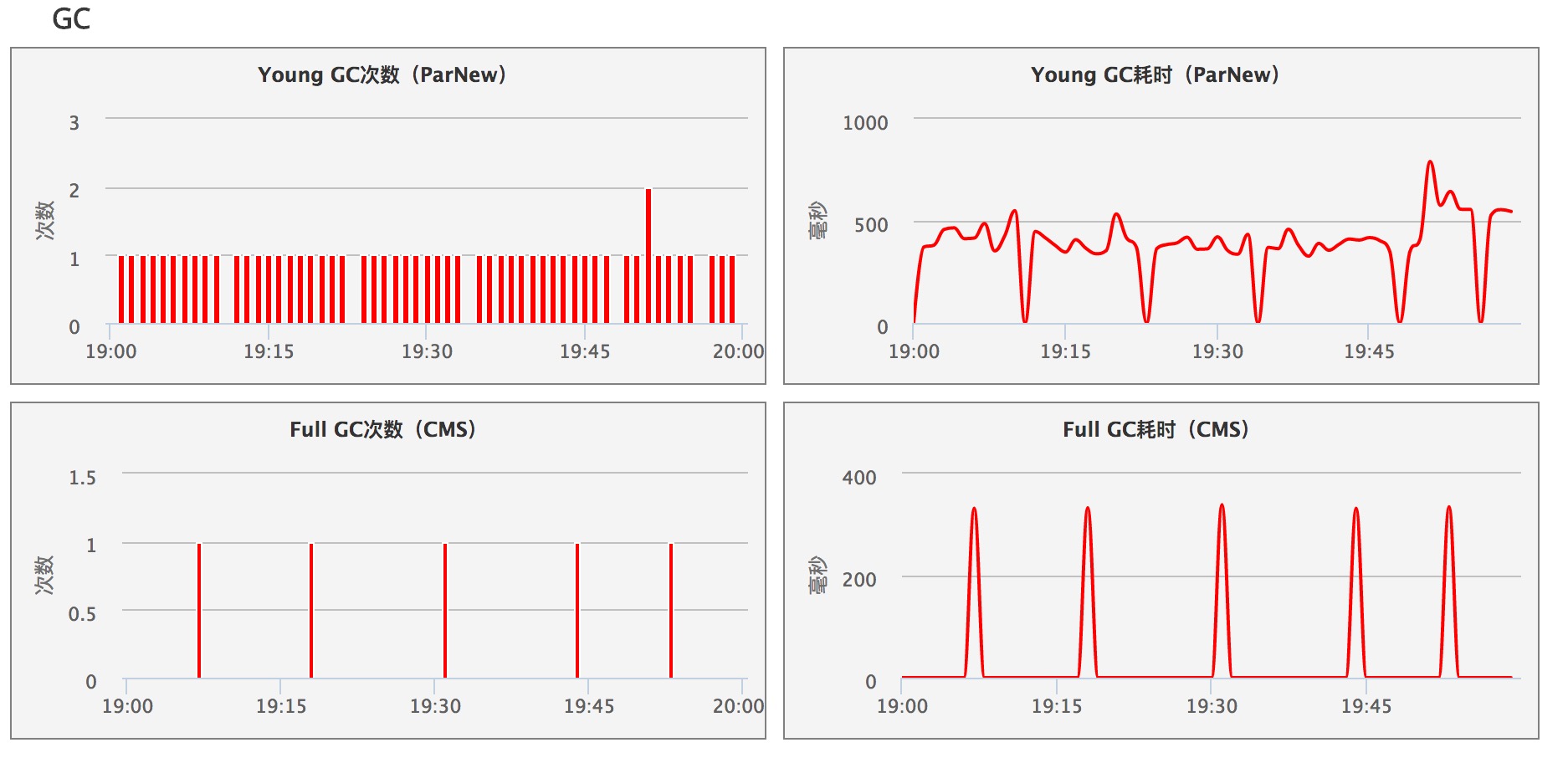
(图一 调优前)
从图中可以看出: YGC 平均一分钟一次,YGC每次耗时在4、5百毫秒左右。 OGC一小时五次,每次耗时300ms左右。
对于Apollo这种最底层的中间件,显然GC表现一般。
JVM全面剖析
市面上JVM分析工具很多,比如JConsole、Memory Analyzer Tool等。这里我们使用的是JDK7之后自带的工具JMC(Java Mission Control)。
启动JMC监控
启动JMC监控很简单,只需要在启动应用的时候加入以下两个系统变量。
-XX:+UnlockCommercialFeatures -XX:+FlightRecorder
需要说明的是:JMC是通过事件机制来监控JVM,所以对JVM侵入很低,性能影响很小,可以忽略不计。
生成黑匣子
大家都知道黑匣子,在飞机上用来记录飞机运行数据的设备。JMC也可以生成一个黑匣子用来记录JVM运行数据。命令如下:
jcmd ${PID} JFR.start duration=60s filename=/tmp/myrecording.jfr
需要切换到启动应用的用户,否则会失败。比如configservice是deploy用户启动的,那么必须切到deploy用户,切换用户命令如下:
sudo -i
su deploy
以上命令的意思是监控60s,并记录到/tmp目录下的myrecording.jfr文件里。
分析黑匣子数据
在命令行里输入
jmc
就会启动分析器,然后打开上一步中的黑匣子(myrecording.jfr)。如下图所示:
(图二 JMC截图)
JMC功能非常强大,这里大致罗列一下比较实用的功能:
- 查看JVM参数、系统变量
- 按类查看TLAB中分配情况
- 创建对象的堆栈信息
- 按线程查看TLAB中分配情况
- TLAB详细信息。TLAB数、最大TLAB、最小TLAB、平均TLAB大小、TLAB分配内存、分配速率
- 查看一次GC各个阶段的耗时
- 查看热点代码
- 查看热点线程、锁竞争相关
- 本地文件IO、Socket IO
这里简单介绍一下TLAB(Thread Local Allocation Buffer)。由于Heap不是线程私有的,所以在Heap上分配对象内存的时候必须要加锁。TLAB就是为了减少锁,给每个线程单独分配的空间。分配对象内存的时候优先从TLAB空间上分配,如果TLAB空间不够才会从外部共享空间分配。从JMC上也可以看到在TLAB里、外分配对象的比例。如果对象在TLAB外分配的多肯定是有问题的。
Heap信息
调优前Heap信息如下图所示:
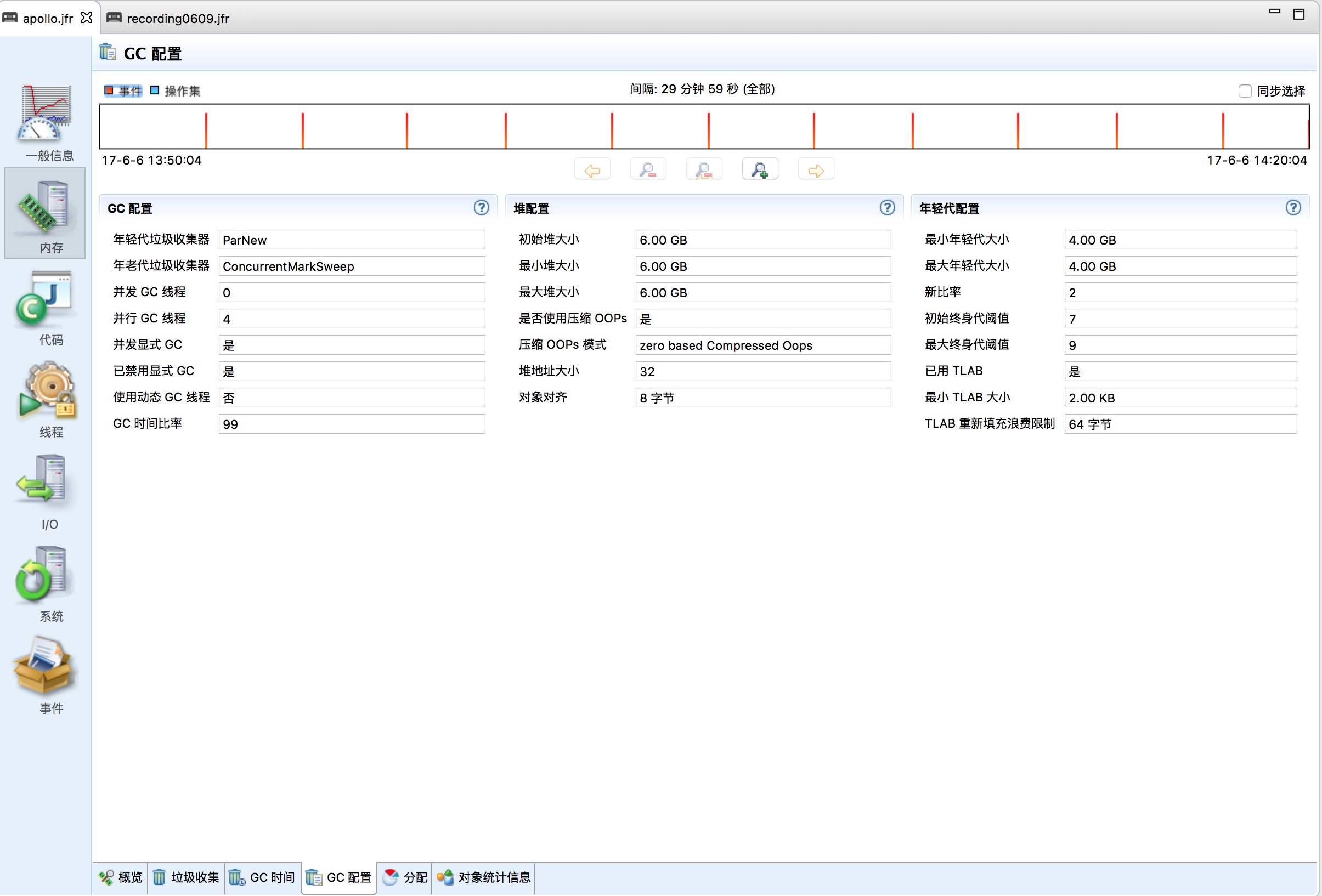
(图3)
从图中可以看出:堆总大小为6G、新生代大小为4G。老年代大小1.7G左右(2G - 方法区)
Eden区中分配最多的对象
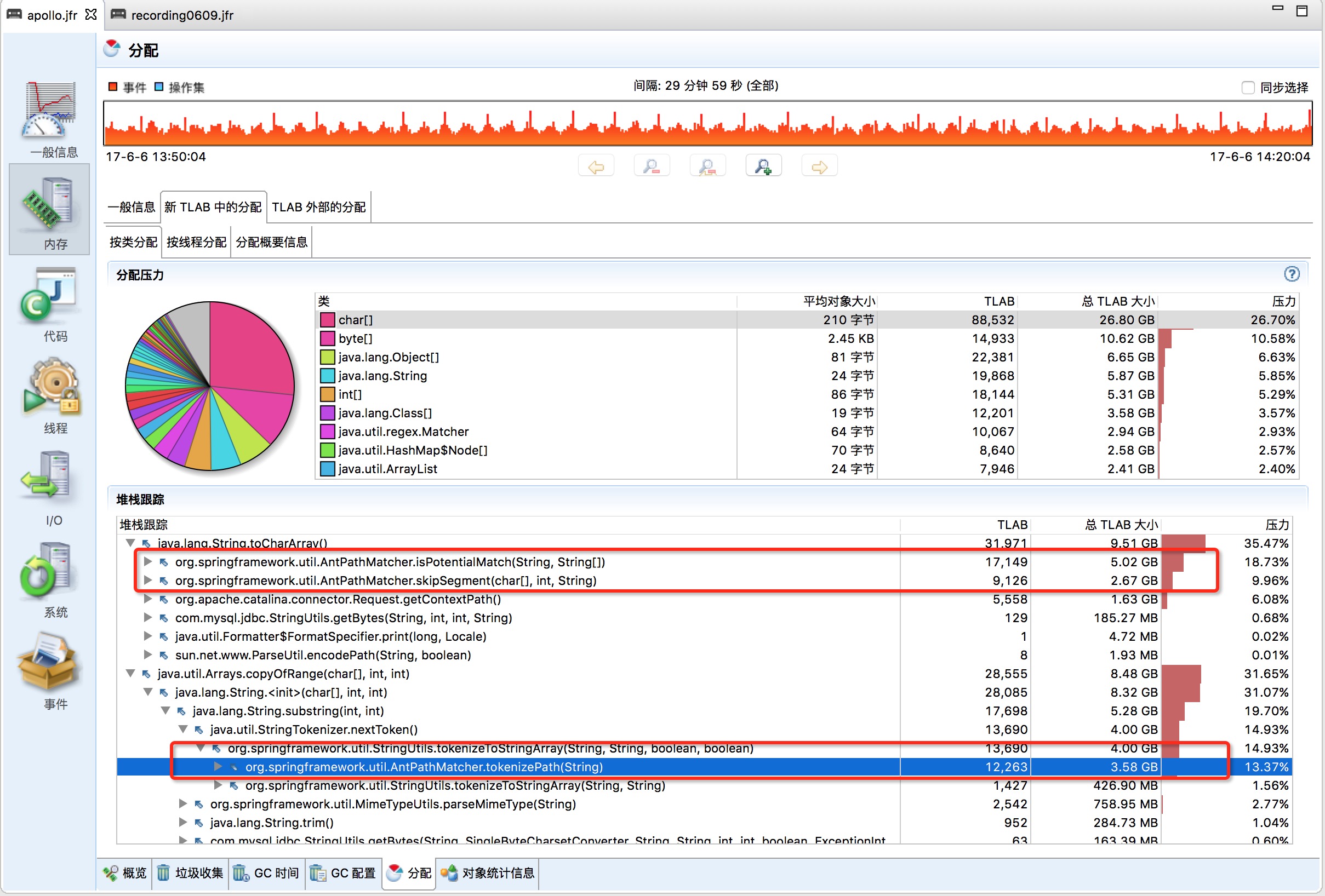
(图4)
从图中可以看出,创建最多对象的类是:char[] 和byte[]。这里很好理解,对象本质上就是内存中一块内存空间,并且到最后都是由基本类型组成。基本类型中char和byte又是使用最多的。 从红框中可以看到,创建char[]对象最多的代码是springframework.util.AntPathMatcher类的isPotentialMatch。找到热点分配对象代码就可以debug源码,看一下这一块逻辑为什么会创建如此之多的char[]。 isPotentialMatch和skipSegment方法代码如下:
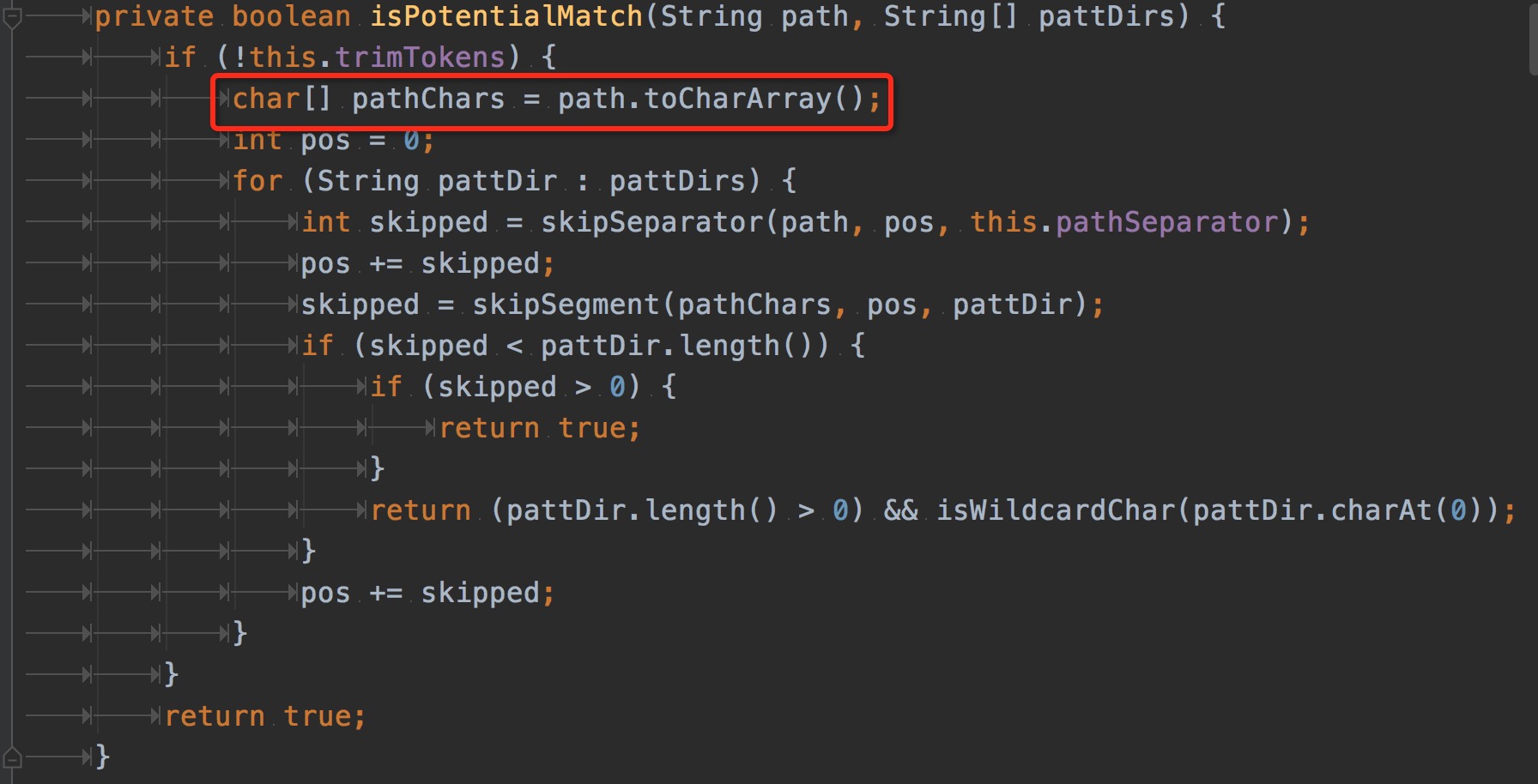
(图4)
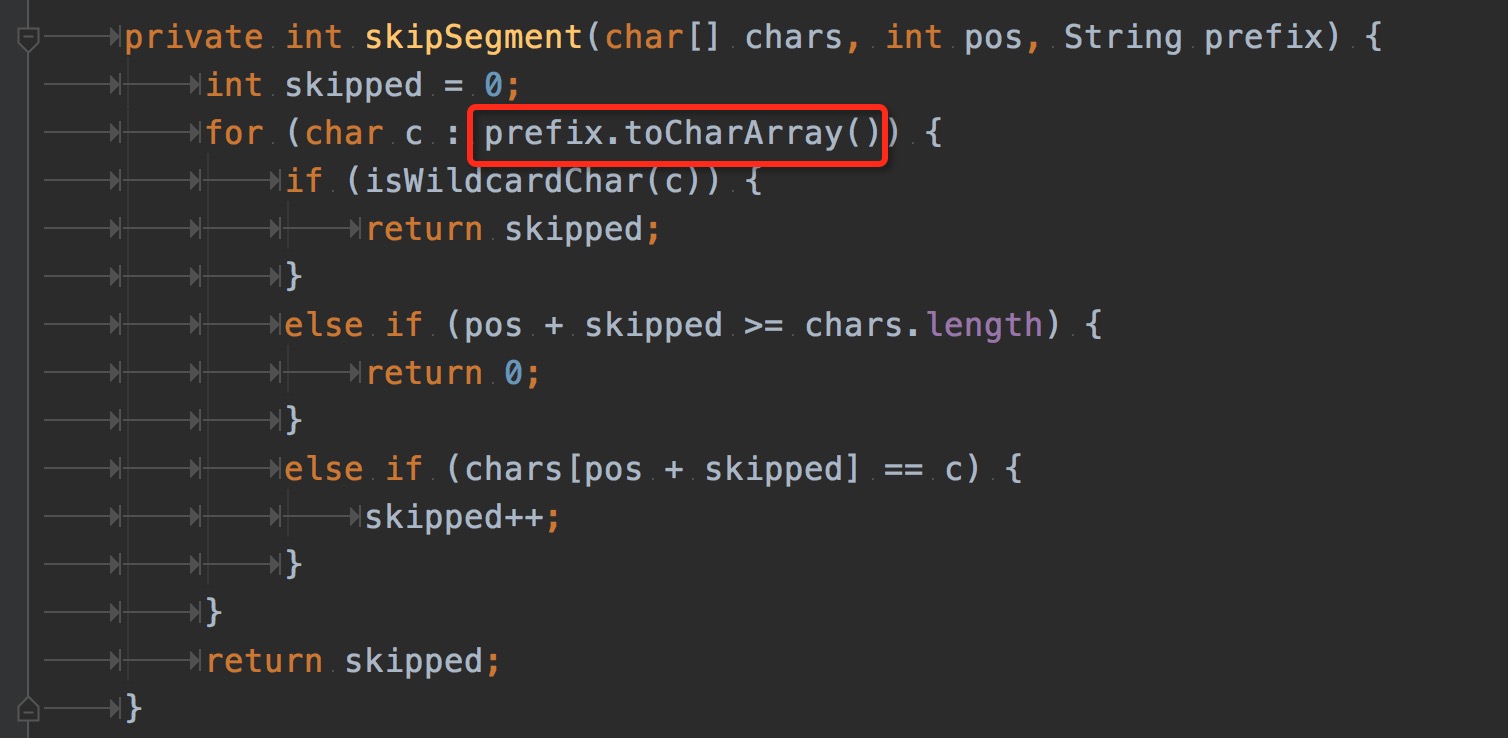
(图5)
这里的代码逻辑是spring mvc处理一个request matcher的过程。但是matcher目标集合并不是我们自定义的controller,而是spring boot、spring mvc内置的Endpoint。

(图6)
endpoints.enabled=false
management.port=-1
关闭之后,YGC频率从一分钟一次变成两分钟一次。效果还是很明显的, 但是OGC并没有减少。其实也很好理解,上诉提到的char[]是典型的“短命”对象, 在每一次YGC的时候肯定能被回收掉,所以只能起到减少YGC的效果。
查看按线程分配对象
JMC可以按线程的维度查看对象分配情况,如下图所示:
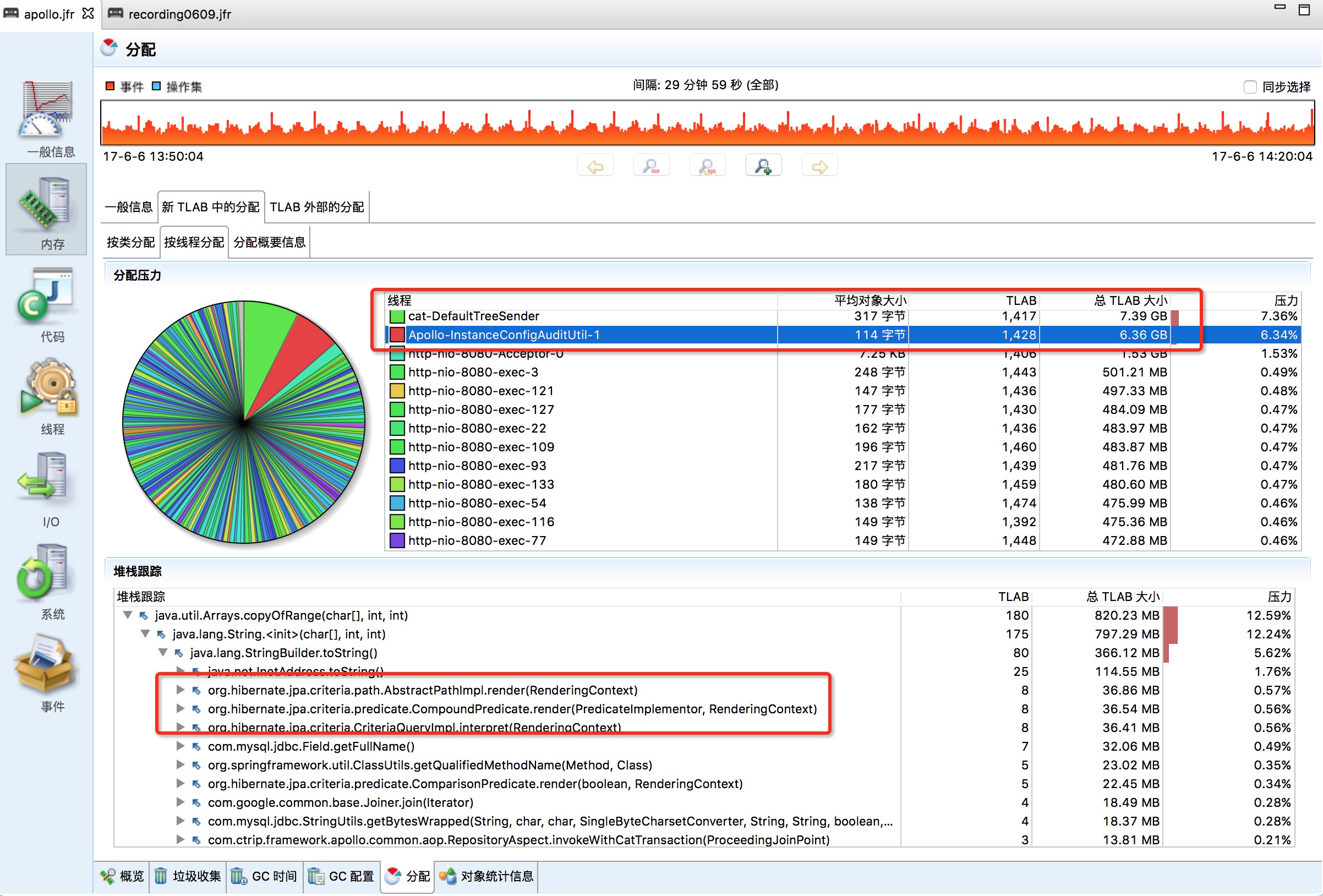
(图7)
可以看到分配对象前两位是cat-DefaultTreeSender和Apollo-instanceConfigAuditUtil-1。其它线程从名字上看就是tomcat的http线程了。这里就发现为什么Apollo-instanceConfigAuditUtil-1会创建那么多对象呢?同样追踪堆栈,发现jpa创建了很大一部分。Apollo项目中使用spring-data作为DAL层框架。从Cat上看,这个线程执行的两个SQL QPS达到57。
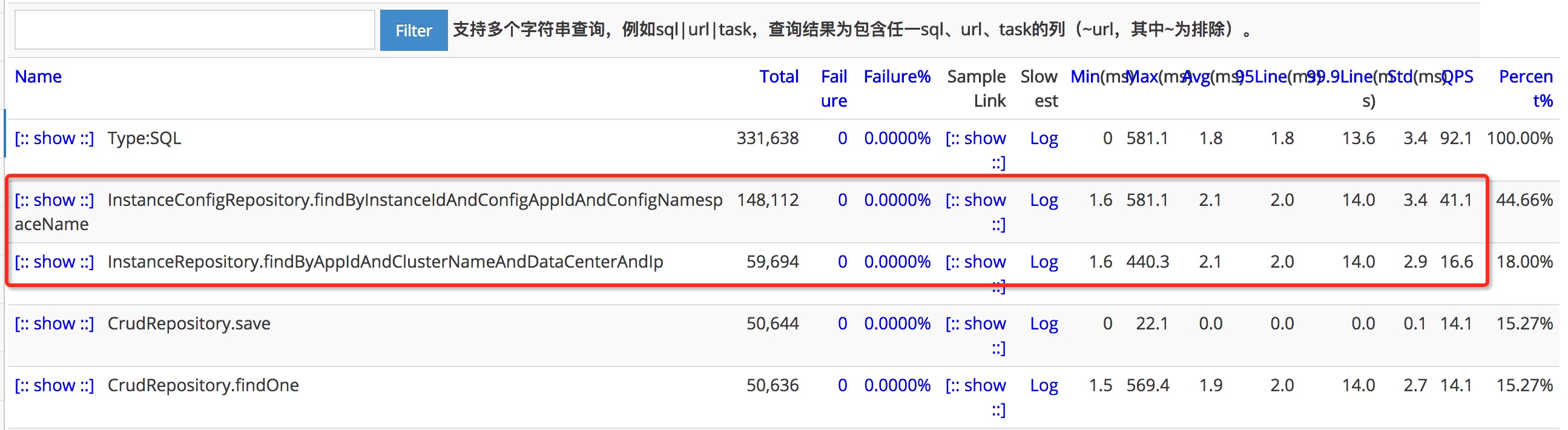
(图8)
分析GC日志
下图是截图的一段GC日志:
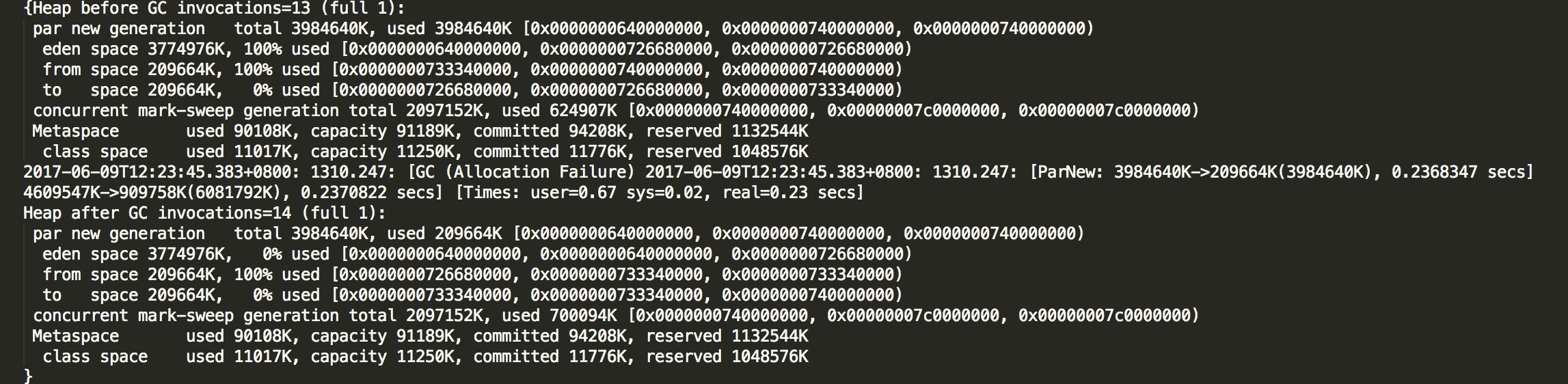
(图9)
- eden区大小为:3774M
- Survivor区大小为:209M
- 此次GC,Survivor区溢出
- 老年代大小为2G,此次GC之后老年代已使用内存从624M增加到700M
- 大对象直接分配在老年代
- 持久对象在多次YGC之后还未被回收(缓存对象)
- 一次YGC Survivor溢出会导致升级到老年代的生命阀值变少,也就说溢出的“老对象”直接被转移到老年代
显然这次GC有第三种对象进入到老年代。这种情况下进入到老年代基本上都是短命对象。所以针对这种情况,可以调大Survivor区大小。 对于上述提到的第二种情况,可以调大eden区大小减少YGC频率,也就是减慢对象成长速度。当然,减少对象创建是最直接、最有效的方式。
所以调整完JVM参数之后各个区的大小为:Survivor区500M * 2,Eden区4G,Old区2G。 效果如下图所示:
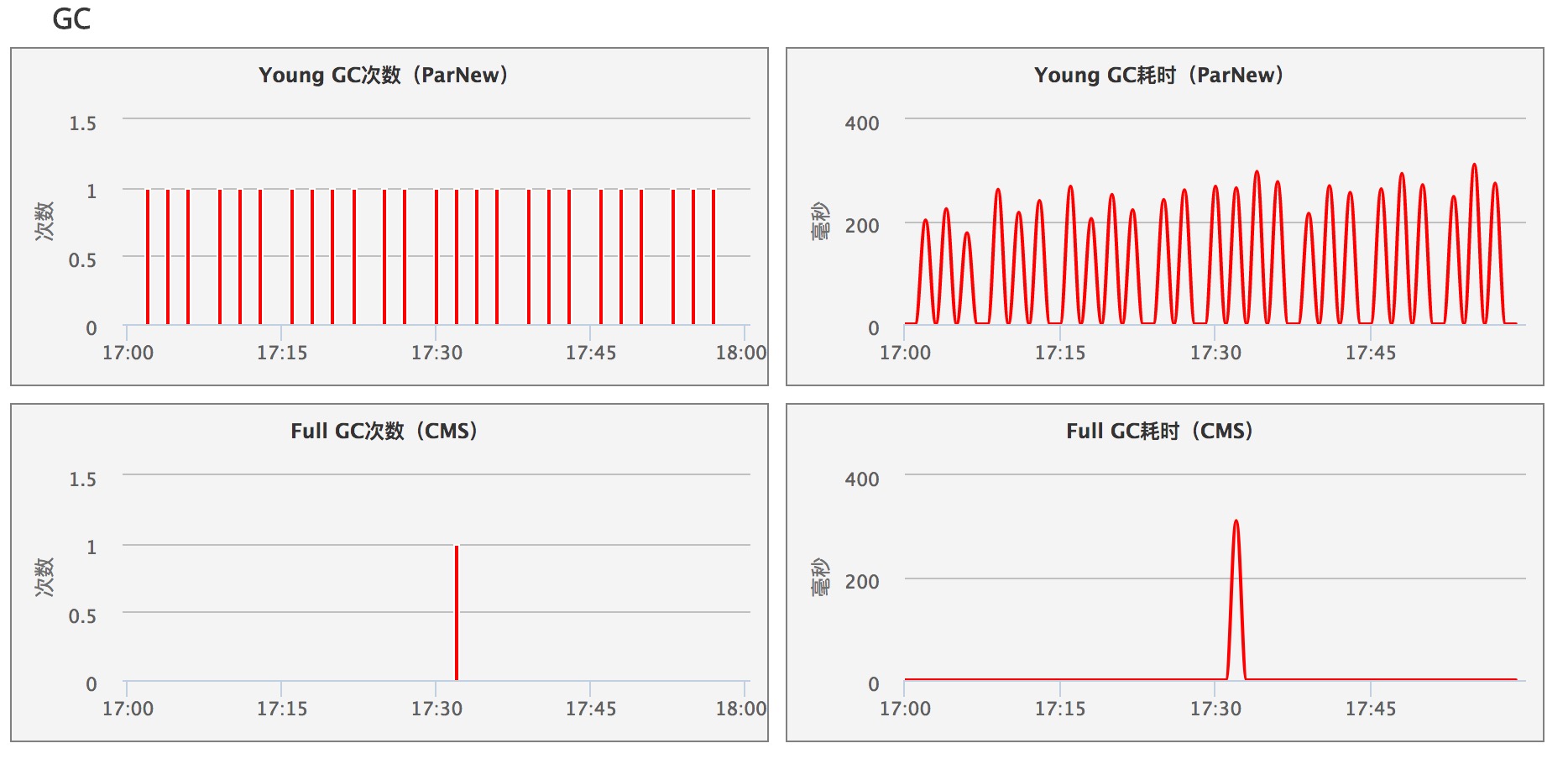
(图10)
| 大小 | 时间 |
| 100M | 70ms |
| 200M | 135ms |
| 300M | 180ms |
| 400M | 250ms |
内存copy并不会导致Stop The World,所以久一点也是能够接受的。但是目前还有一个问题没有解决,为什么OGC还是会存在,理论上只有系统中的缓存会持久存在在老年代,其它对象在YGC阶段就会被回收掉。这个问题,由于时间问题,没有得出结论,后面有时间会继续分析补充上。
至此,Apollo GC调优第一阶段就完成了,从效果上看还是比较明显的。后续会继续分析OGC的原因。